 en
enLibrary
More details about 1.7 Terabyte Firebird SQL database
Alexey Kovyazin, 26-May-2014
Some days ago we have published an article about our tests, devoted to the relationship between Firebird performance and databases growth, where we have tested (among others) the 1.7 Terabyte Firebird SQL database. Here you can find more details about such a big database.
Tables
In the table 1 you can find list of tables with key characteristics. This statistics was taken with gstat –a –r and interpreted with our IBAnalyst tool.
| Table | Records | RecLength, bytes | Data Pages | Table size, Mb | Indices size, Mb | Total, % |
|---|---|---|---|---|---|---|
| ORDER_LINE | 6300024797 | 60.09 | 38880344 | 607505.3 | 50582.3 | 34 |
| STOCK | 2100000000 | 298.88 | 43783806 | 684121.9 | 15809.61 | 39 |
| ORDERS | 630004141 | 29.00 | 2692324 | 42067.56 | 4250.38 | 2 |
| HISTORY | 630000434 | 48.77 | 3446455 | 53850.86 | 0.00 | 3 |
| CUSTOMER | 630000000 | 577.52 | 24226054 | 378532.0 | 8675.78 | 21 |
| NEW_ORDER | 188999981 | 13.00 | 623764 | 9746.31 | 1260.84 | 1 |
| DISTRICT | 210000 | 103.92 | 1860 | 29.06 | 1.27 | ~0 |
| ITEM | 100000 | 82.73 | 756 | 11.81 | 0.52 | ~0 |
| WAREHOUSE | 21000 | 97.90 | 179 | 2.80 | 0.11 | ~0 |
Table 1. Tables and their main parameters in 1.7Terabyte Firebird SQL database
As you can see, the biggest table is ORDER_LINE – it contains more than 6 billion of records. It’s size is about 600Gb and there are 50Gb of indices for this table. This table occupies 34% of the database.
Table STOCK is also very big – it contains ~2 billion of records. Though the record number is smaller than in table ORDER_LINE, STOCK occupies ~680Gb in the database (39%), because record length in STOCK is 298.88 bytes against only 60.09 bytes in ORDER_LINE. Accordingly, size of associated indices for STOCK is only 15Gb.
The third biggest table, CUSTOMER, has even bigger record length – 577.52 bytes, and occupies 378Gb (21%) with only 630 million of records.
Indices
There are not many indices in this database, since it is designed only for tests – majority of tables have only 1 index – primary key. In the real world applications developers create many indices to serve particular users requests, but here indices are concentrated on the fastest inserts and updates of the data – as a result, indices size is only 5-10% of table size, while usually it is 30-50% (if you have indices size more than 50% of the table size, consider redesign of database schema, or, may be, drop useless or non-effective indices).
In the table 2 you can find the list of all indices in this database and their key characteristics, taken from gstat statistics and analyzed by IBAnalyst:
| Index | Table | Depth | Keys # | Key length, bytes | # of unique keys | Size, Mb |
|---|---|---|---|---|---|---|
| ORDER_LINE_PK | ORDER_LINE | 4 | 6300024797 | 1.41 | 6300024797 | 50582.34 |
| STOCK_PK | STOCK | 4 | 2100000000 | 1.00 | 2100000000 | 15809.61 |
| ORDERS_PK | ORDERS | 3 | 630004141 | 1.01 | 630004141 | 4250.38 |
| CUSTOMER_LAST | CUSTOMER | 3 | 630000000 | 0.00 | 1000 | 4029.64 |
| CUSTOMER_PK | CUSTOMER | 3 | 630000000 | 1.01 | 188999981 | 1260.84 |
| NEW_ORDER_PK | NEW_ORDER | 3 | 188999981 | 1.01 | 188999981 | 1260.84 |
| DISTRICT_PK | DISTRICT | 2 | 210000 | 1.37 | 210000 | 1.27 |
| ITEM_PK | ITEM | 2 | 100000 | 1.00 | 100000 | 0.52 |
| WAREHOUSE_PK | WAREHOUSE | 2 | 21000 | 1.00 | 21000 | 0.11 |
Table 2. Indices of Firebird 1.7Tb database
As you can see, all indices have very small key size – the biggest is 1.41, it means that index is very effectively compressed – for example, primary for ORDER_LINE contains 6 billion of keys in 50 Gb of space. This is very good result.
There are 2 indices which have depth = 4. It means that engine need to perform 4 reads of index pages to find requested value. It is recommended that index depth should be not higher than 3, and if it is higher, database page size should be increased. However, we already have the maximum page size in this database (16Kb), so we need to live with it.
Heating
Before we will continue with queries, let's perform “heating”. When database is big, system data, associated with tables, are also big, and it takes some time for Firebird to cache necessary system pages. For example, table ORDER_LINE has 10110 pointer pages. Heating is necessary for any big database.
Without heating the first execution of queries will take significantly longer than with heating.
To heat database cache, let’s perform series of simple queries to load system data into cache:
select first 1 * from ORDER_LINE;
select first 1 * from STOCK;
select first 1 * from customer;
select first 1 * from ORDERS;
select first 1 * from ITEM;
This is enough for such a simple data schema. For big and complex databases with hundreds of tables heating schema could be much more complex, it should be carefully developed.
As a result, memory consumption of Firebird process (Firebird SuperServer 2.5.2 64 bit) grows:
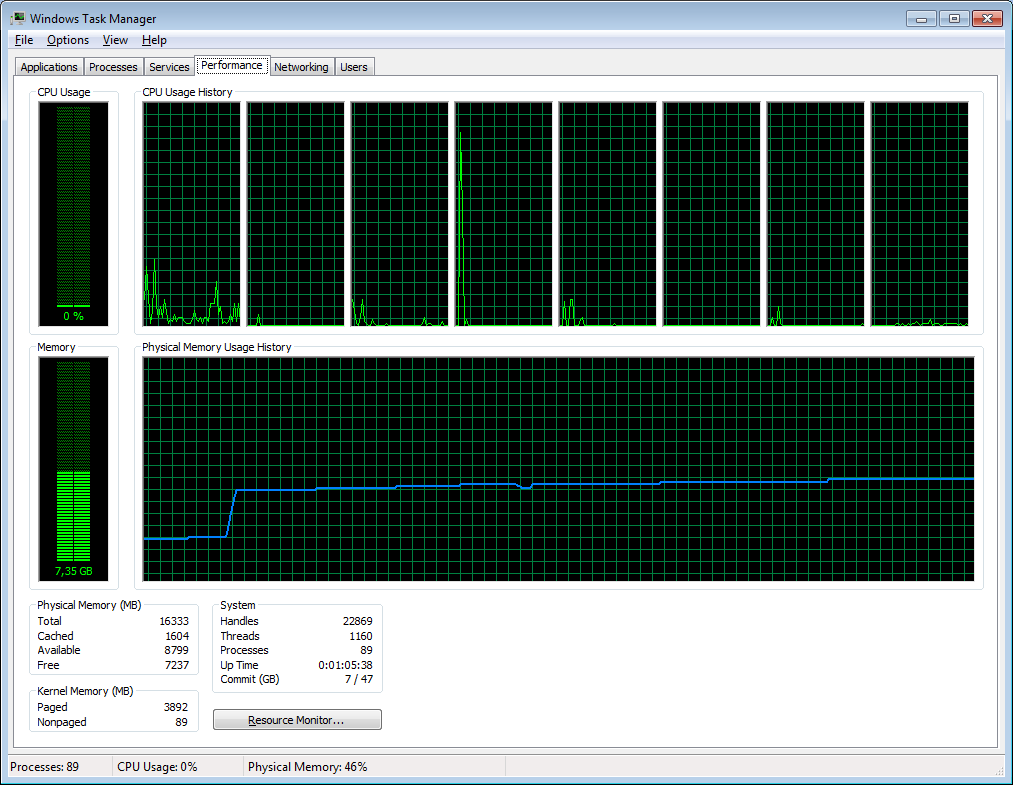
Figure 1. Heating of database cache
Queries
After heating we can run several typical queries to estimate how users will work with such a big Firebird database: what will be response times for typical queries and read operations.
| Query | Plan and statistics | Description |
|---|---|---|
select first 10 w_id, w_name, c_id, c_last |
PLAN JOIN (WAREHOUSE NATURAL, |
Join table WAREHOUSE (21000 records) with CUSTOMER (630 million records), with condition for specific warehouse |
select count(*) |
PLAN JOIN (WAREHOUSE INDEX (WAREHOUSE_PK), |
Count records for the previous query. |
SELECT first 10 * |
PLAN (ORDER_LINE INDEX (ORDER_LINE_PK)) |
Query to the largest table ORDER_LINE (~6billion records) with condition to select order_line records for specified warehouse id. Since primary key ORDER_LINE_PK is composite, and contains warehouse ID (CONSTRAINT ORDER_LINE_PK: Primary key (OL_W_ID, OL_D_ID, OL_O_ID, OL_NUMBER), it is effectively used in this query. |
SELECT count(*) |
PLAN (ORDER_LINE INDEX (ORDER_LINE_PK)) |
Count for previous query. The second query with the same parameters will be much faster, but queries with different parameters show similar result. |
Select first 10 w_id, w_name, c_id, c_last |
PLAN JOIN (WAREHOUSE INDEX (WAREHOUSE_PK), |
Query with join and 2 conditions. |
select first 10 c1.C_ID, c1.C_FIRST, c1.C_LAST, o1.O_ID, |
PLAN JOIN (C1 INDEX (CUSTOMER_PK), |
Query to show details for specific customer in the specific warehouse and district. It demonstrates performance of more complex joins. |
Summary
As you can see, 1.7 Terabyte Firebird database shows pretty good performance for common read queries. If query is well-designed and uses good indices, performance is good even on the very big database. Of course, there are pain points, like long fetch time for very large datasets and long time for count operations (since Firebird visits all pages to get an exact number of records for the particular query in the specific transaction), but these pain points are well-known by experienced Firebird developers, and there are methods to design database in the way to workaround them.
But what about performance degradation for inserts and updates? Is it possible to compensate it with smart tuning of Firebird configuration?
In the next article we will consider tuning options for Firebird 1.7 terabyte database – we will boost our bird and make it fly.