 en
enLibrary
Database physical structure (InterBase and Firebird)
Alexey Kovyazin, Sergey Vostrikov, last update 05-June-2004
Database physical structure
Why do we have to study InterBase database physical structure?
Usually, when we speak about InterBase database physical structure we mean that it represents data from the point of view of low-level data organization – right up to the level of bytes. Many programmers developing applications using high-level language neglect studying low-level details. However, knowing main principles of data organization inside the database is a key to the effective design of database applications. Therefore we will have excursus into insides of InterBase database organization and we will find out how it is arranged.
So, what is database management system (DBMS) intended for? Obviously for storing and controlling the data. It sounds banal, but it is worth thinking about. A user put the data to DBMS, which in some way translates these data to understandable for it internal formats. You can imagine “0 and 1 ”If the words “internal data format ” cause some difficulties with associations. DBMS stores these data, and at the time of first demand must extract them from its format, convert into a suitable view and give it to a user.
The subject of this chapter is how DBMS stores its data, in what view and how they are organized on the lowest level. We’ll try to explain to you how from bits and bytes, lying on HDD, we get valuable data.
InterBase database files
Usually, when we speak about a database we mean DBMS itself and user information, and even clients` programs that work with data. In this chapter, we will consider a database as database files.
InterBase database represents one or several files containing information about all that is connected with this base. Information about users is an exception because users are defined at the level of the whole server and are stored separately, in security database admin.ib (tt was ISC4.GDB in pre-7 versions).
Advice: Look at chapter “ Server and Database Security ” to study more about InterBase security principles.
So, all information about the database is stored within these files: data itself, indices, triggers, stored procedures etc.
InterBase database for an average project represents one file because modern InterBase versions can use 64bitIO to operate with datafile and it gives you the ability to have datafile up to 64Gb. Earlier versions of InterBase had the constraint of 4 gigabytes per each database file (up to 64 Tbytes for the whole database). As we can suppose, 64 gigabytes are quite enough to store information of almost any database application. But if it is necessary, we can divide a database into several files. By the way, there are InterBase databases of hundreds gigabytes size.
IBSurgeon – a guide through InterBase database
We have to know in detail the structure of InterBase database files. And therefore it is desirable to have any convenient tool that allows working directly with database files, not by means of InterBase server kernel. The easiest way is to use an ordinary hexadecimal viewer and try to understand the structure of database files considering its HEX-representation. It would be rather tiresome work.
But fortunately, there is a tool for a direct work with InterBase databases. It is an IBSurgeon Editor – a tool for a direct low-level work with InterBase databases, which can be used for studying the internal structure of InterBase databases and diagnosing corrupted databases in order to restore them. For more details see appendix «Administrator and InterBase developer tools».
IBSurgeon uses its own alternative mechanism of database access that allows open and reviews databases at any state, including heavily corrupted that can’t be opened by InterBase/FireBird/Yaffil server kernel.
We will use IBSurgeon to illustrate the internal structure of the database.
Files *.IB/*.FDB from within
IB is an extension, recommended for InterBase database files, and FDB for Firebird (previously it was GDB). The first thing we have to say about the structure of IB file is that it represents a set of pages of strictly defined size. The size of the database file is divisible to a page size, which is unaltered for all files of this database. Different InterBase versions support different page sizes, what is shown in table 1. The page size is set when creating a database and can’t be changed during its living cycle. In other words, we can change a page size only when restoring a database from a backup.
Table 1. Page size supported by different InterBase versions
|
InterBase version |
Page size, bytes |
||||
|
1024 |
2048 |
4096 |
8192 |
16384 |
|
|
InterBase 4.0 |
* |
* |
* |
* |
|
|
InterBase 5.x |
* |
* |
* |
* |
|
|
InterBase 6.x-7.x |
* |
* |
* |
* |
|
Reading and writing of data in a database are executed page by page, many important server and database characteristics such as a size of database cache depend on a page size and counted in « pages ».
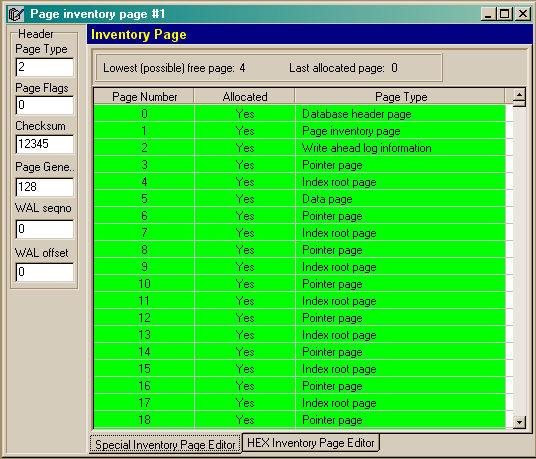
Let’s open any InterBase database by IBSurgeon. It’s enough to click twice the database file. Picture 1 expresses a list of pages that appear after IBSurgeon has opened the database:
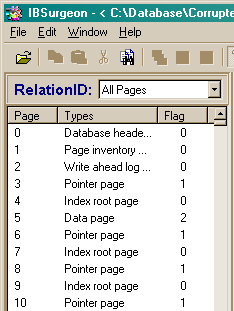
Picture 1. A list of database pages
Pages can be of different types, each of which serves its certain aim. Interdependences of different types are conditionally represented on picture 2. Picture 2 schematically depicts an allocation of pages in database file – from left to right, top-down, if counting from the beginning of the file. Pages of the same type don’t go strictly one by one – they can be easily mixed, allocated in a file in the order they were created by a server when extending or creating databases.
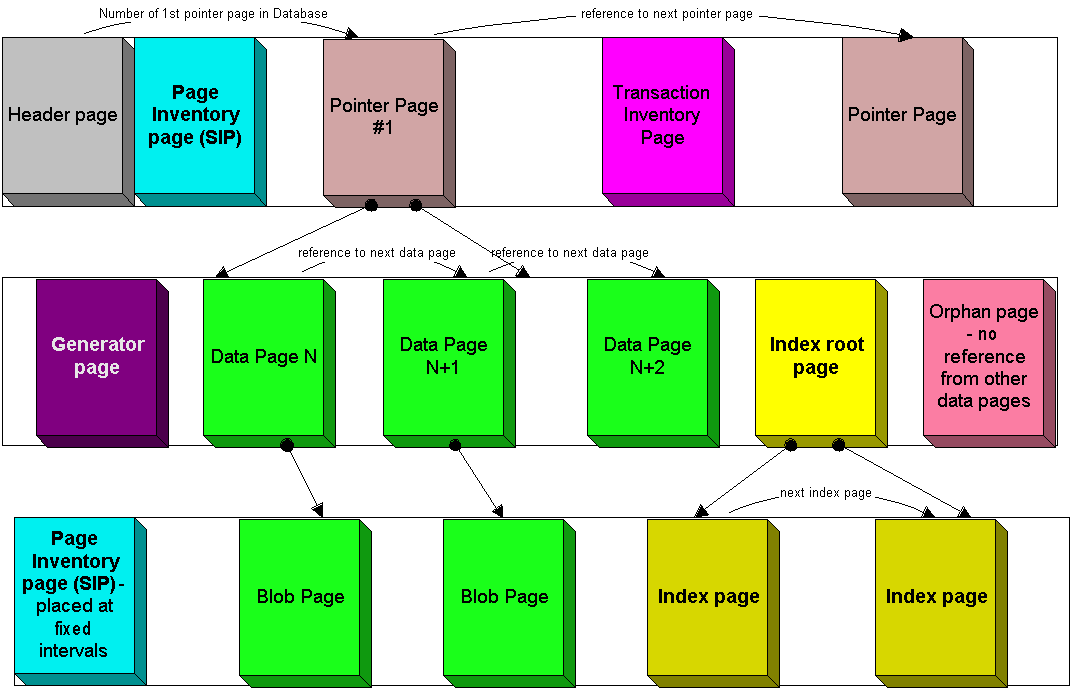
Picture 2. Interdependences between different types of pages in InterBase database
You must have noticed that some types of pages have no references to other types of pages. However, there is no contradiction here, the matter is that these types of pages are linked and used at the other structural level. They can be linked to RDB$PAGES table and other system tables (this table and other system objects we’ll consider below – in chapter «Database logical structure »). On picture 2 we can see only explicit references among the pages at the physical level.
Let’s consider in detail what types of pages there are in InterBase database. In ods.h file from the set of InterBase primary codes there is information about all possible types of pages. We’ll frequently refer to this file to receive the data not only about ODS but also about many other fundamental things of InterBase kernel at the original source. 11 types of pages are declared in all, but only 9 of them are worth being explained (we can clearly see it from table 2). Page types with identifiers 0 and 1 are undefined or not used.
Table 3. Page types in FB
|
The definition in ods.h |
Page type identifier |
Page descriptions |
|
pag_undefined |
0 |
Undefined - If a page has this page type it is probably free
|
|
pag_header |
1 |
Database header page |
|
pag_pages |
2 |
Page inventory page (or Space inventory page - SIP) |
|
pag_transactions |
3 |
Transaction inventory page (TIP) |
|
pag_pointer |
4 |
Pointer page |
|
pag_data |
5 |
Data page |
|
pag_root |
6 |
Index root page |
|
pag_index |
7 |
Index (B-tree) page |
|
pag_blob |
8 |
Blob data page |
|
pag_ids |
9 |
Gen-ids |
|
pag_log |
10 |
Write ahead log information |
Every page has its header, containing information about a page type and a number of the next page of the same type. We can get the complete list of parameters that every page header contains, if we consider pag structure in file of definitions ods.h.
/* Basic page header */
typedef struct pag {
SCHAR pag_type; /*page type identifier*/
SCHAR pag_flags; /*page flags*/
USHORT pag_checksum; /*page checksum: it equals 12345 after 5.0 version */
ULONG pag_generation; /*page generation */
ULONG pag_seqno; /* WAL seqno of last update - deprecated*/
ULONG pag_offset; /* WAL offset of last update - deprecated*/
} *PAG;
Page types and their using
Let’s consider every page type in detail and get to know about their function and information they contain. We will start step by step – from the first page.
Any operation with a database begins from the reading of database header page (or header page). Database header page goes first in all databases file. Accordingly, it is represented first on picture 2 (if we imagine that the picture represents an extension of database file from left to right, top-down)
A header page contains information about a database on the whole. On picture 3 a data page is expressed in the way IBSurgeon shows it to us:
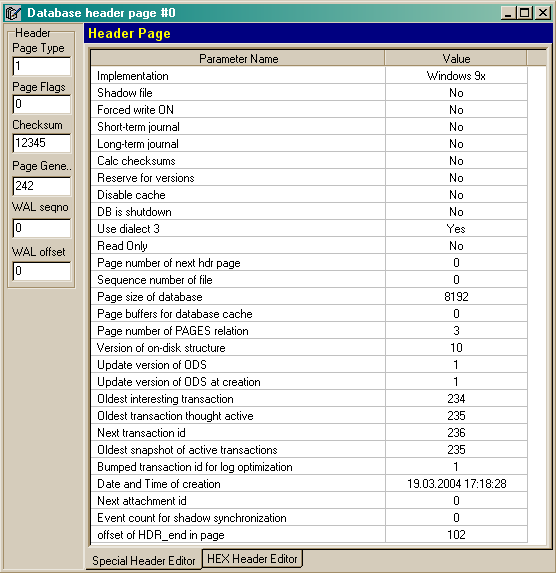
Picture 3. Database header page.
You can get the idea of header page contents, having received database statistics. For this, you can use the utility of command line gstat or another more convenient tool for InterBase administration from the list in application «Administrator and InterBase developer tools». For more details about the process of receiving statistics and description of the header, page data see chapter «Statistics».
It should be noted that header page contains such important information as page size, number of ODS version (information about it you’ll find below), data of database creation, information about transactions and a set of different information. For example, Implementation ID stores information about under what operating system this database was created.
When connecting a database, InterBase server reads first 1024 bytes of information from the beginning of the file and defines according to read values whether the file pointed out in the connection line is InterBase database or not. Then server reads the number of ODS version from a header page and page size in this database and, if ODS version is compatible with server implementation, it rereads the whole header page, using the proper page size, received from the first 1024 bytes. After it, the rest important database parameters such as read-write mode, database dialect and etc are read from the header page.
On header page there is a reference to the first of the pointer pages, storing references to data pages that contain metadata: RDB$Pages table (see below in chapter «InterBase database logical structure»). On picture 2 this reference is illustrated by an arrow with inscription «Number of the 1 st pointer page in database». The server reads the number of the 1 st pointer page from the header page and goes on to it. Pointer page consists of a well-ordered array of data pages numbers that make a certain table (a table is considered as SQL-object, described by database logical structure). Now you can see how IBSurgeon interprets the pointer page (look picture 4):
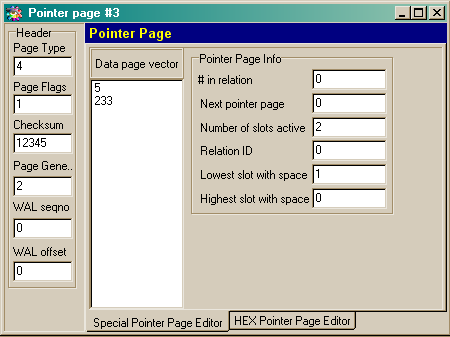
Picture 4. InterBase database pointer page
The page contains a data page vector; these data make a certain table in a database. This vector represents an array of pointers corresponding to the numbers of data pages in the file. The server reads a 4-byte number of the data page and goes on to a necessary data page. When it goes on to the 1 st data page of RDB$Pages, the server starts constructing the internal database representation that is used later by the server for all operations with the database. RDB$Pages store references not only to data pages containing information about the database but also to the rest pages that play a part in providing database work.
We often mention this table that strictly speaking relates to database logical structure. Nevertheless, everything is interconnected, therefore we can’t describe something not referring to something else.
One of the important page types is transaction inventory page (TIP). These pages like all the pages consist of a header and main part representing an array of 2-byte sequences. The sequences describe a state of transactions in a database (for more details about transactions see chapter «Transactions »).
Table 4. Possible transaction states in TIP
|
Value of sequence on PIP |
Sense |
|
0 |
Transition has not started, active or lost without commit or rollback |
|
1 |
Transition executed Commit |
|
2 |
Transition executed Rollback |
|
3 |
Limbo-transition (for 2PC) |
Every record version has its transaction identifier, what allows simultaneously executed transactions to «learn» about the state of each other and solve the conflicts during a multi-user work (see chapter “Multi-generation architecture of InterBase” to know more about record versions and other staff).
Database header page, pointer pages, and TIP refer to «housekeeping» page types, used only by the server. InterBase users never explicitly get the information they contain. Pages that store information about the allocation of pages (usually they are mentioned as Page Inventory Pages (PIP) or Space Inventory Pages (SIP)) refer to housekeeping page type as well. These pages are located beginning from the second, that is first PIP goes just after a header page, and appear in a database in fixed page intervals of other types. The size of these intervals means what number of pages of other types PIP appears, and depends on page size set for this database. Page Inventory Pages are not accounted on Pointer pages and are not pointed out in RDB$Pages. The integrity of these pages is vital for a successful work of the whole base because PIP contents describe the state of all the rest pages in the database. Every database page can have 3 states: not allocated, allocated with space, allocated and full. When there is a necessity in additional space for new data, the server checks PIP for the purpose of having not allocated pages. If there is such a page, server modifies its state into allocated with space. If there are not allocated pages, database expands – a new data page is added.
An example of the data page in IBSurgeon and the data it contains is given in picture 5.
As soon as the page is allocated, InterBase writes its state on SIP and then writes the page itself. After it, we have to add this formed again page to some great number of pages, for example to data pages for a table. For it, we should write the reference to this new page on the last page of this great number of pages – for example, on the last data page of a table. If server interrupted its work just after writing on SIP, but not writing the reference on pages, which refers to the just allocated page, then this page becomes orphan. An orphan page is physically created, reserved on SIP, but there are no references to it from other pages, it means that server will fail to find it and write data on disk. The orphan page is marked by the red square on picture 2. Orphan pages mostly arise as a result of server’s unexpected power down and are «cured» by the special tool for database repairing gfix (or by FirstAID) (or by IBSurFirstAID).
Before considering data pages, we should mention about important page types: generator and index pages. Generator pages represent an array of 4-byte numbers, showing generators states. Actually, the generator is an ordinary counter.
On picture 6 you can see a generator page. Pay attention that although IBSurgeon shows generator names, it doesn’t these names are stored on generator pages. It is made so for the convenience of the user, studying database. In reality, generator names are stored in system table RDB$Generators.
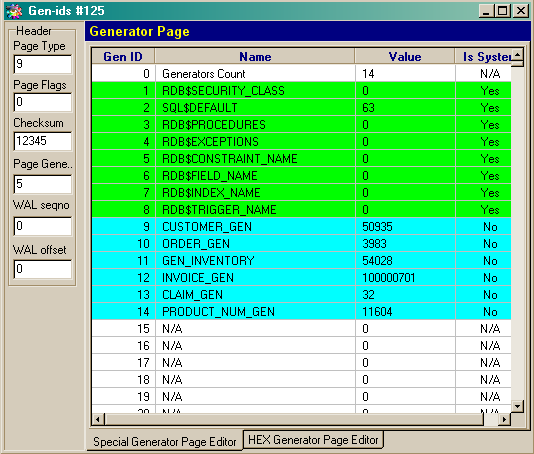
Picture 6. Generator page (g en-ids )
As you see in this example database contains system generators, beginning with the RDB$ prefix, and user-defined generators. If you want to know about function and use of generators when developing InterBase database applications, see chapter «Tables. Primary keys and generators». Generator pages are accounted along with other pages in RDB$Pages table.
Every table has at least one index root page, no matter whether it has indices or not. This page contains pointers to index pages for a proper table. We may say that index root page is of the same importance for index pages as pointer page for data pages. Therefore IBSurgeon represents it in a similar way. An example of index root page is given in picture 7.
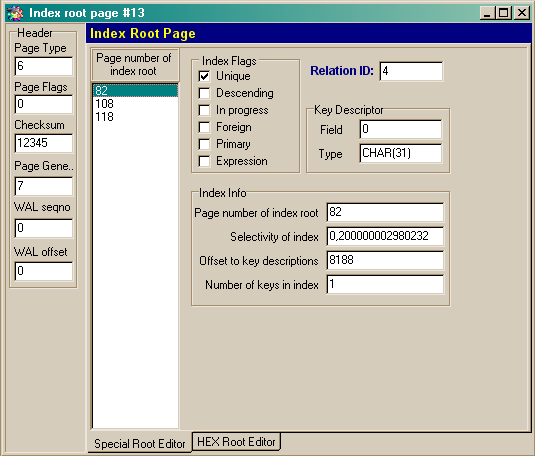
Picture 7. Index root page
Index root page contains a list of pages where index values are stored, as well as index information – selectivity of the index and different flags. For more details about indices, their role and usage in InterBase databases see chapter «Indices».
Index pages contain directly values of indices, or if index level >0, references to the underlying index pages. Here is an example of index page (picture 8).
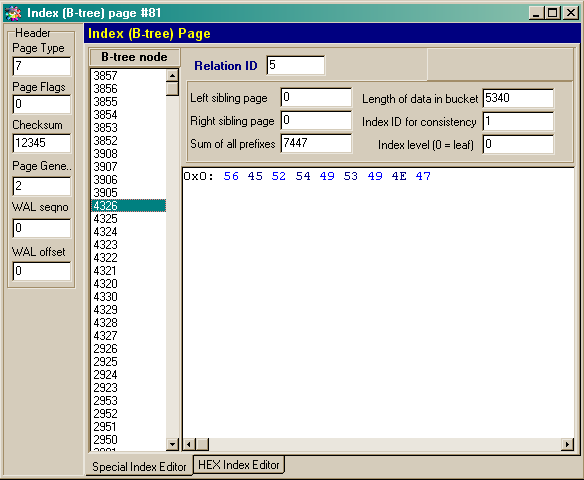
Picture 8. Index (B-tree) page
Index page stores packed values of indexed data. Rather complicated mechanism of indexation is used, especially when making compound indices (including several fields).
In general data pages and pages containing BLOB-values store user information. Data pages contain records in user tables of the database, fragments of records, old versions, differences between versions, BLOB-fields and so on. As for BLOB-fields, they are connected with records on data pages and contain data of large size, that can’t be located on the data page. Reference type of storing BLOB-values allows storing large data.
An example of data page presentation in IBSurgeon is given in picture 9:
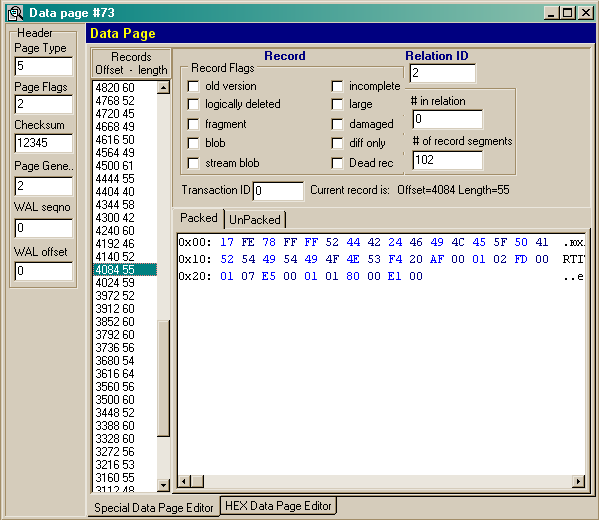
Picture 9. Data page
Data page header contains page type, owner table identifier (relationID). Records are stored on data pages from the end of the page and they are allocated closer to the beginning of the page as they are filled.
We can make sure of it, if we look at row indices, containing 2 values – offset on the page and its length. As you see at the beginning of the row there are records, allocated at the end of the page – for example, first record has offset of 8156 bytes and length of 34 bytes – therefore it ends 8156+34=8192 bytes – on the very brink of the page (in our case page size is 8192 bytes). When the page is filled (with data from the top and record indices from the bottom), the server starts writing new records and versions of old records for new pages. From the mechanism of page fill described above, we can easily say why InterBase specialists emphatically recommend using data pages of big size (4096 bytes at the minimum, better 8192). If we create a table one record of which will be of rather a big size (for example 10 fields of VARCHAR (255)), they will occupy, be filled, more than 2550 bytes. It means that such record will be too big for a page of small size (1024 or 2048). It is obvious that a necessity to load several pages from disk to read one single record will not quicken the work with your database. Thus it is recommended to redefine the size of data page when creating or restoring a database because the size of 1024 bytes is set by default. We have just considered briefly the major types of InterBase datafiles pages and their function. Now we can go on to a higher structural level.
ODS
ODS is an abbreviation for On-Disk Structure, that is the data structure of InterBase database on disk. ODS defines how the data within the database files are organized. Definition of main constants and data structures for implementing On-Disk structure is in the file from the set of InterBase source codes ods.h. ODS was being changed during the process of InterBase development, and when working with a concrete database, the server finds out the number of ODS version to know what it is dealing with. ods.h file represents us the following versions of On-Disk structure:
-
ODS 5 was used by InterBase 3.3 and is not supported by versions above
-
ODS 6 and ODS 7 never came out
-
ODS 8 is used by InterBase 4.0
-
ODS 9 is used by InterBase 4.5 and above
-
ODS 10 came out with InterBase 6
-
ODS 11 came out with InterBase 7.0
Apart from major ODS versions, there are minor versions that depend on a concrete version of the database server, which created them. Major numbers of the version are written in the whole part of the number, indicating the version, minor – in the fractional part. For example, server version 4.0 creates databases, having ODS 8.0 and InterBase 4.2 – 8.2. The transition between minor versions bottom-up is executed automatically. For example, it’s enough to open a base with ODS 8.0, created by server 4.0 by InterBase 5.6, and ODS of this database will have version 8.2. The transition between major database versions is executed only through database backup, using an old version and restore, using a new server version. The process of transition between versions is described in detail in chapter 1.4 «Migration».
The important moment in the implementation of ODS support for InterBase versions 4.x and 5.x is a backward compatibility of InterBase servers 4.x and 5.x with version one unit less than the implementation of a concrete server. InterBase supports several possible ODS, and according to its ODS version when connecting to the concrete database, chooses support of required ODS implementation. The mechanism of making a decision about what implementation of ODS support to choose in a concrete case is called Y-Valve ((c) of Steve Trenton).
Easier saying, a database with ODS 8.x, matching InterBase 4.0, can be opened in InterBase 5.x.
Full ODS compatibility table is shown below:
|
InterBase version |
Major ODS |
Minot ODS |
|
4.0/4.1 |
8.0 |
... |
|
4.2 |
8.2 |
8.2 |
|
5.0/5.1 |
9.0 |
8.2 |
|
5.5 |
9.1 |
8.2 |
|
5.6 |
9.1 |
8.2 |
|
6.0 |
10.0 |
9.0/9.1 |
|
7.0 |
11.0 |
10.0 |
|
7.1 |
11.1 |
10.0 |
ODS has downward compatibility.In other words server with higher version and all its tools will manage to work with a database created server early versions, but not the contrary. If you try to open a database, created in the 6 the InterBase version, by InterBase 5.x, you’ll receive an error message «Unsupported On-disk structure: Found ODS 10, supported ODS 9».
Description of transition between versions bottom-up and conversely see in chapter «Migration».
ODS is very important for issues concerning backup and database extraction, as well as restoration of damaged databases. Tools of backup gbak and restore gfix watch ODS version and just won’t work, if ODS version of the database, which they must serve, is larger than version implemented in them. It means that gbak from 4.x won’t be able to create a database backup if it is created by server 5.x, however easy to the contrary.
A bridge between database physical and logical structure
We considered a physical structure of database files in a general way. Now we have to go on to database logical structure. Let’s make a bridge between physical and logical levels of information representation in a database so that there is no delimitation in the notions and no gaps in the material. Everything that is stored in different database pages must be organized someway in computer memory; data from database file must be converted into a set of intraserver objects and variables. This set is called an internal database image according to Ann Harrison terminology [1]. So, we’ll try to consider the process of making internal database image.
-
The server reads 1024 bytes from the beginning of the file and if it is really InterBase database file, it defines page size of this base and rereads the whole header page.
-
From the header, page server extracts the number of pointer page that stores references to data pages, defining RDB$Pages table.
-
Server goes on to this pointer page and starts reading information from the pointed data pages. It fills the first RDB$Pages table with data. This table is something like a bridge between physical objects – pages of database files and logical – tables. Structure of RDB$Pages like other system tables is strictly fixed in InterBase.
-
Having received data about page allocation by relations (relations – in fact, it is the same as ordinary tables, and we may substitute these notions mentally for simplification), InterBase begins to form data structures: at first system tables, constraints and indices, then and user objects.
-
After initialization of system and user metadata (tables, constraints, indices and other database objects), InterBase returns the handle of this database to the user, who asked to open a database. In the main handle is an identifier that shows InterBase what database to work with because a few users can work at the same time and it means that a few databases can be opened.
-
After these operations, the database is considered opened and the server is ready to execute user queries to it. Now when a certain bridge is made, connecting database physical and logical structure, we can start studying the peculiarities of logical structure.
InterBase database logical structure
The logical structure is rather a vague notion, therefore we’ll try to master key ideas gradually, hoping that later they will be intuitively clear. The first we’ll consider relating to database logical structure is system tables and their contents. System tables describe the system, as well as user metadata. Generally speaking, term «metadata» means «data describing a set of data». Prefix «meta» means: «describes a set». For example, meta language is a language, describing a set of languages. Metadata describe user data, that is tables, triggers, views, stored procedures and so on – everything that implements the rules of storing and processing the information, because of which this concrete database is created.
It’s rather funny to know at the first time that all the metadata – user tables, triggers, views, as well as all system objects – are stored in the same tables, from which you can read and write data by ordinary SQL-queries. These tables differ «visually» only by the fact that their names begin with RDB$. These 4 symbols are reserved for the names of system objects. Not a single user table, column or other object have the right to have names beginning with these symbols. Formally you can create a table, the name of which begins with the reserved symbols, but InterBase documentation doesn’t recommend doing it.
A question arises: if the data about database structure are stored in the same tables as the user data, then where is the information about the tables describing tables stored? A classic example of the problem of «hen and egg» - how could one appear earlier than the other, if they are interdependent? The answer is that system tables in their primitive state is fixed in initial InterBase codes and are automatically opened when creating a database in a definite order. We have already spoken about RDB$Pages table that compares physical pages in database files with definite objects of this database. Structure of this table is given below:
Table 5. System table RDB$Pages
| Column name | Datatype | Description |
|
RDB$PAGE_NUMBER |
INTEGER |
Number of physical page |
|
RDB$RELATION_ID |
SMALLINT |
Identifier of table, for which the page is allocated |
|
RDB$PAGE_SEQUENCE |
INTEGER |
Number of this page |
|
RDB$PAGE_TYPE |
SMALLINT |
Page type – see table 3 |
Every data page is related to a certain table. This relation is supported by RDB$RELATION_ID field, where a reference to the table is stored. As it was described above, in the process of constructing internal database image server makes this table and fills it with data according to a set algorithm. To be accurate, at the moment of constructing internal database image RDB$Pages is not a table, it’s just a data file of definite format, known to InterBase. According to a fixed algorithm server reads data from this file and makes a table - RDB$Relations - that is important for the whole database. This table describes all database tables. If we perform SQL-query:
SELECT * from RDB$Relations
to find out references to what tables RDB$Relations contains, we’ll see that it contains RDB$Pages and it itself. It is obvious that in this case server is cunning a bit, substituting these and other system tables in RDB$Relations by backdating, legalizing them in that way. Server logs them as «normal» tables, where it can add or delete records. In other words, provides a standard SQL interface for work with metadata.
And a rather reasonable question may arise – why would InterBase developers adjust their system data in accordance with the user interface? You see, internal mechanisms of access and reading operations would be quicker. Of course, there is a great sense in providing a universal mechanism of work with tables, describing metadata.
The matter is that database logical structure consists not only of tables but also of other objects. There are the following objects in InterBase:
-
Table
-
View
-
Trigger
-
Computed_field
-
Validation
-
Procedure
-
Expression_index
-
Exception
-
User
-
Field
-
Index
-
User-Defined Function (UDF)
Yet we don’t know for sure the function of some objects, but we know for sure that all of them must be described and stored in some view, convenient for the user and for access from InterBase kernel. Best of all would be to save these objects in system tables. Their addition and modification are performed by SQL queries. A smart solution, isn’t it? Server implementation is completely separated from a concrete database – all interconnections are described by SQL and its extensions – the language of stored procedures and triggers.
So, all server objects are stored in tables. Every type of objects has the table, describing all the instances described in the database. For example, for triggers there are a table RDB$Triggers, for stored procedures - RDB$Procedures, views are described in table RDB$Relations.
Let’s consider in detail the structure of the last table, describing all the tables and views in a database. The structure of the table RDB$RELATIONS is taken from Language Reference for InterBase 6 and is given below in table 6.
Table 6. System table RDB$Relations
|
Column name |
Datatype |
Length |
Description |
|
RDB$VIEW_BLR |
BLOB |
80 |
BLR: for views, contains BLR (Binary Language Representation) of the query, which InterBase performs every time when applying to view. |
|
RDB$VIEW_SOURCE |
BLOB |
80 |
Text: for views, contains the code of SQL query that implements this view. |
|
RDB$_DESCRIPTION |
BLOB |
80 |
User description of table or view |
|
RDB$RELATION_ID |
SMALLINT |
|
Contains internal identifier of table/view |
|
RDB$SYSTEM_FLAG |
SMALLINT |
|
Defines the type of table: user data — 0; System information > 0. |
|
RDB$DBKEY_LENGTH |
SMALLINT |
|
Length db$key |
|
RDB$FORMAT |
SMALLINT |
|
Reserved for InterBase internal using. Contains modification counter of metadata for the given table. |
|
RDB$FIELD_ID |
SMALLINT |
|
The number of fields in the table. |
|
RDB$RELATION_NAME |
CHAR |
31 |
Unique table name. |
In the description of this system table, we see an abbreviation BLR. To understand what it is, we’ll have excursus into SQL. As it is known views, triggers and stored procedures is a code, written in an extension of SQL language (for every DBMS server there are their own extensions). It is close to human language, what allows making queries in it easily. But InterBase, obviously, translates it into something more «machine» - namely into BLR Binary Language Representation). Any query, view, trigger, the stored procedure is always translated into BLR and then transmitted to InterBase kernel for execution.
BLR
BLR is a special language, used as an intermediate link between SQL-code that a programmer writes and a machine code server admits. Nobody writes directly in BLR – it would be rather difficult because for the highest possible running speed in this language so-called returning Polish record is used. Here is a small example:
blr_begin,
blr_assignment,
blr_field, 0, 7, 'D','A','T','E','I','Z','M',
blr_variable, 1,0,
blr_assignment,
blr_field, 0, 4, 'R','A','T','E',
blr_variable, 0,0,
blr_block,
BLR for your queries, procedures, triggers and other triggers is formed by the special preprocessor that is a part of server kernel. As it is shown in table 7, for views their text (initial) view, as well as compiled view, that is BLR, is stored. When referring to any object, having BLR, the server executes a binary code of the object, and it doesn’t interpret the initial text of these objects every time, what allows quickening the execution of complicated queries.
Hierarchy of objects in InterBase
To have a clear idea of what database objects represent, we’ll try to make a hierarchy of database objects according to the principle «who contains and what». Physical pages of database files are first that have to be included in our hierarchy as the lowest level of data organization. Then tables go as basic objects, describing all the rest types of objects. Tables describe stored procedures, triggers, calculated fields, validations, expression indices, exceptions and so on. Pay attention – only describe! Tables contain only declarations and definitions of these objects, and objects are implemented through BLR. Therefore we can represent tables in the form of a frame, supporting all the other database objects. BLR will be at the bottom of the frame as the layer of implementation, then triggers, stored procedures, expression indices, and views.
To calm down the specialists on InterBase internal structure, who can object that BLR of many objects (such as views) are stored in system tables, we’ll comment that this attitude is rather difficult to express on a picture, and for simplification turn it down. The scheme doesn’t have the aim to recreate interdependences of database objects absolutely accurate; it just illustrates their close interconnection.
The fact that these object types are directly connected with BLR, which implements them without any intermediate logic, unites them. Exceptions should be allocated separately – they represent special types of mistakes, defined by the user. Exceptions are processed at the level of InterBase kernel and therefore don’t have BLR. Such types of constraints as checks are allocated above triggers because in reality triggers implement the logic of constraints and checks.
A hierarchy of objects of database logical and physical structure is painted on picture 2.]
Picture 10. Objects of InterBase database logical structure
Of course, this scheme describes the logical structure and interconnections of objects in the database only approximately and makes a general idea of it. Everyone who wants to study the structure of InterBase database metadata can execute reengineering of database system tables and consider all interconnections between its objects, as well as apply to documentation and InterBase primary codes. This table shows only main database objects. Let’s describe briefly the main functions these objects perform in the database.
Tables – the main object, containing user and system data. A table has a unique name and contains a set of named fields. A user can place data, extract and modify data in tables. We may say that table is similar to ordinary paper tables drawn by hand.
Triggers – executable parts of the code, used for implementing additional actions at the time of data operations. Triggers are executed before or after insert, modification or delete operations, and allow realizing substitution of values into created again records and many other things.
A stored procedure is a powerful tool for implementing business logic at the level of the database. Being executed at the level of the server, it works very fast and allows executing a set of operations over data sets. InterBase stored procedures return standard SQL data sets, over which all SQL operations, including unification with other tables.
Views are compiled SQL queries, executed on server. Views allow organizing data sets, transferring a part of business logic on server.
Validations are constraints set on values of fields in the table. For example we can point out that the given field will accept only positive values. Constraints on field values are implemented by triggers and allow controlling effectively the reference integrity at database level. Usually constrains are used to prevent a table from placing of wrong values to it.
Users – InterBase allows us to have several users for work with database and distribute the rights of access to different database objects among them. Thus, we can control resolutions to these or those database operations.
User-Defined Functions (UDF) – functions, defined by user. It’s one of the most powerful InterBase capabilities, allowing us to extend a standard SQL interface by its own functions. For example, functions of work with lines such as UPPER (setting all symbols in the upper register), are implemented in standard UDF-library, included to InterBase set. Thanks to a possibility to create own UDF, developers can extend InterBase functionality practically by any functions. We can use any programming environment that allows creating dynamic libraries (Visual C++, С ++ Builder, Delphi etc) for creating UDF.
Conclusion
In this chapter we’ve considered the questions about implementation of storing and processing of data within InterBase database for the first time. Unfortunately, we can’t make a brief review of this theme not applying to a great number of terms and inaccurate analogies. If we described database physical and logical structure in more detail, we would have to relate to InterBase primary codes anyway, but it would be another book.
Nevertheless, we think it would be useful for every programmer to become acquainted with the contents of the product he uses every day.
Bibliography
1. «The On-Disk Structure of InterBase» by Ann.W.Harrison
2.«Space Management in InterBase» by Ann W.Harrison
3. «Structure of a Data Page» by Paul Beach (With thanks to Dave Schnepper and Deej Bredenberg)